记录下 MarkdownView 的性能优化
我的开源项目 MarkdownView 的 0.2.0 版本 终于发布了!
改版本带来了性能上的巨大进步:
Performance
- Rendering is now at least 3x faster on ALL DEVICES.
- Real-time previewing is now much much smoother.
- Scrolling is much quicker and smoother with no frame drop.
- Memory usage has been reduced by 30%
借此机会,记录下我的优化思路。
前期表现
- 启动、初次渲染耗时长
- 渲染完成后上下滚动的时候掉帧严重(使用懒加载模式)
- 渲染完成后上下滚动的时候内存占用量太大了(关闭了懒加载模式)
- 用作“实时预览”的时候会卡,导致输入体验很糟糕
综合以上表现,新功能部分也已经定型了,所以决定好好优化下性能,
至少在我这台 2019 款的 MacBook Pro 上不要有明显的卡顿吧…
渲染性能优化
定位问题
我想先来介绍下 MarkdownView 的整套渲染流程,
如图所示:
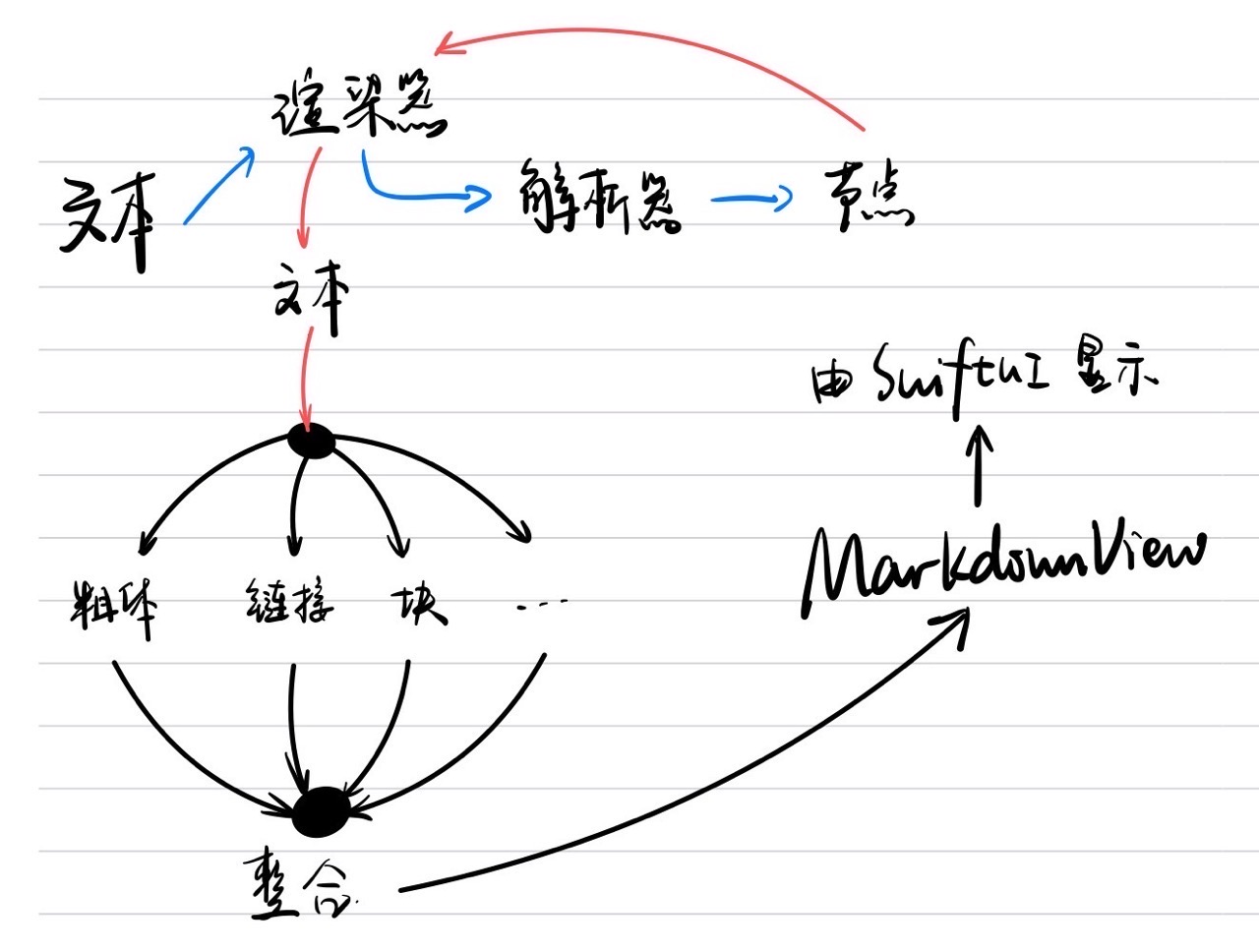
本来以为是在最后整合的时候 Layout 反复运算导致速度慢,
最后我用我第一篇博客测试了下,启动渲染居然需要 20s,
属于是完全卡住的感觉,在 Xcode 中能看到 CPU 占用持续在 100% 左右,
最后定位到 分词模块 耗费了大量 CPU 时间,
这就是优化的重点了!!
问题分析
分词模块的作用是保证文本都能以很短的形式呈现,
用于实现合理的自动换行,
但是分词模块依赖 Natural Language 框架进行分词,
本质上就是机器学习的分词,需要时间来完成,
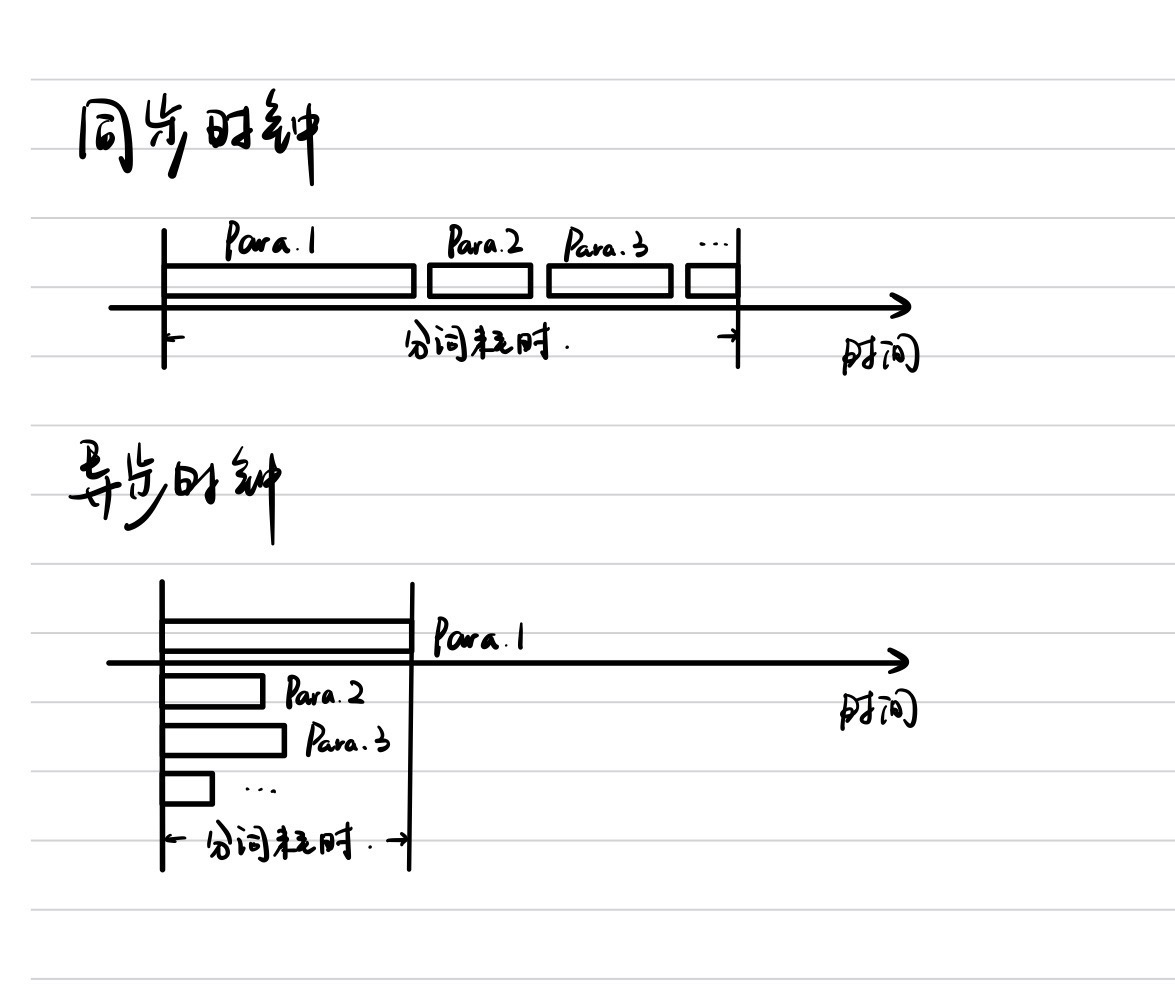
同时所有的代码都是 同步执行(sync) 的,
上一个结束了才会执行下一个,
段落一多,大量的时间都被浪费在一段段分词了。
解决思路
- 异步执行(async)所有的分词操作,这样可以让所有段落的分词同时开始
- 文本渲染使用单独的
TextView来渲染,默认显示空白等待分词结束后自动排版
还是用我的第一篇博客作为测试,加载速度从 20s 缩短到了 1s,内存占用也下降了 20%。
这也是我为什么会在新版中弃用 懒加载 (Lazy Loading) 的主要原因。
实时预览性能优化
定位问题
这里的问题具体表现在当我连续输入文本的时候,
CPU占用高,并且伴随 输入框 也很卡顿。
问题分析
接着上面的思路,
每次有微小变动的时候,MarkdownView 都会重新走整套流程,
本以为是异步处理得过于频繁导致卡顿,
于是就用Combine做了debounce处理,在输入间隙执行重新渲染,
问题没有解决,
而且,中文输入就没有问题,
重新考虑了下 渲染流程 和 SwiftUI 刷新机制,
每次有变动的时候,都要重新进入解析流程,
英文
不论是多打一个字母或是删除一个字母,都会重解析,
中文
输入拼音时本质上还没有让文本改变,不会重解析,
只有拼音转成文本之后,统一进行一次重解析,
So,
在英文状态下,过于频繁的重解析是导致卡顿的“罪魁祸首”。
解决思路
- 对于一开始的文本输入做 debounce 处理,在输入间隙执行重解析、重渲染。
这样一来,在连续输入字符的时候不会每一次都执行重新解析和渲染,
只有在我输入时的停顿处,才会刷新整个文档,执行一次重渲染,
这样既保证了预览的实时性,也提升了整体性能。
做了debounce延迟,怎么保证预览的实时性?
在真正地连续快速输入的情况下,是不会去看预览的
但凡少许停顿了下(0.3s),MarkdownView就已经自动刷新完成了
避免了在快速输入时,频繁地做无用的刷新
总结
在开发过程中,需要注意:
对于一些比较耗时的部分(比如:下载、大量机器学习预测…)使用异步(async)来完成,
在 UI 出现问题时,关注下 UI 是如何刷新的,
看看是不是有过多繁杂的任务,
重新思考下现实中的逻辑,可以试着降低他们的优先级,
浓缩一下就是:主线程(main thread)不要有过多连续繁杂且无用的运算!!
记录下 MarkdownView 的性能优化
https://liyanan2004.github.io/markdownview-performance-optimization/

